Deep Learning with Class Imbalance
Posted by Rahul Pandey, Angeela Acharya, Junxiang (Will) Wang and Jomana Bashatah. Presented by Zhengyang Fan, Zhenlong Jiang and Di Zhang.
Class imbalance is a problem in machine learning where the number of one class of data is far less than the other classes. Such a problem is naturally inherent in many real-world applications like fraud detection, identification of rare diseases, etc.
Before building any classifier model, it is important for us to deal with the problem of imbalanced data as there are issues associated with it. For instance, let us suppose that we are building a model to identify which transactions are fraudulent, based on the available features. Now suppose that the data is imbalanced i.e. there are 999 examples correspond to non-fraudulent transactions (majority class) and only 1 example corresponding to the fraudulent transaction (minority class). In such a scenario, the gradient component corresponding to the minority class is much smaller than that of the majority class. Thus, while making predictions, the model is biased towards the majority class which leads to inaccurate classification of the minority class.
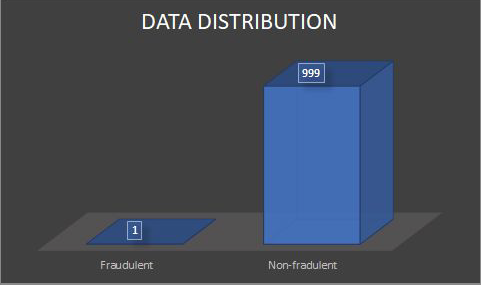
Fig 1. Data Distribution of Imbalanced Data
In this blog, we will mention different techniques that have been used to overcome the data imbalance problem. To be specific, we will talk about the following three approaches:
- Data level method
- Modify the class distribution of training samples
- Over-sampling and Under-sampling
- Algorithm level method
- Modify the learning algorithm and loss function
- Hybrid method
- The combination of data and algorithm level methods
Data Level Method
Data level methods are those techniques that directly modify the class distribution of training samples so as to make them balanced. There are different data-level methods that we can use in practice:
Random Under-sampling: Random Under-sampling balances the data distribution by removing samples from the majority class randomly. While it improves the run time, its major issue is that it may ignore some useful information from the majority class . Also, the chosen sample may be biased.
Random Over-sampling: This approach increases the number of instances in the minority class by randomly replicating them in order to present a higher representation of the minority class in the sample. Although there is no information loss in this approach, there is a chance of overfitting because of the repetition of the minority class data.
Cluster-based Over-sampling: In this approach, we apply a k-means clustering algorithm to both the minority and majority class independently. After clustering, each cluster is oversampled so that all the clusters of the same class have the same number of instances and all the classes have the same size. This method overcomes challenges within-class imbalance, where a class is composed of different sub-clusters and each sub-cluster does not contain the same number of examples. However, just like in random oversampling, this approach has the tendency to overfit the data.
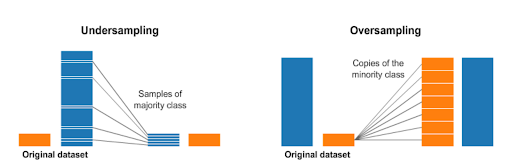
Fig 2. Resampling strategies by cluster-based oversampling for the imbalanced dataset
Dynamic sampling: The approach of dynamic sampling proposed by Pouyanfar, Tao, Mohan and et al. (2018) is slightly more complex than the previous ones. In this approach, we dynamically sample the data as it is being trained. For the experiment, image data has been taken. The proposed model includes a real-time data augmentation module, CNN transfer learning module, and dynamic sampling module that samples data based on F1 scores. We will go through each process in detail next.
First, the data augmentation is done using techniques such as image rotations, flips, brightness, smoothness to generate different samples. Next, the updated samples are passed to an Inception (V3) model. Inception model is a widely-used convolution neural network based image recognition model that has been shown to attain a very good accuracy on the ImageNet dataset. In the Inception model, only the last layer is made trainable as the early layers capture more generic features of the images. Now, as we train the Inception model with the sampled dataset, we compute a new F1-score every time on the test set and compare it with the previous f1 score that we computed using a different sample.
The F1-scores of class in iteration , are calculated as
This will help us decide whether to over-sample or under-sample the data and see which samples actually produce a good result. To find out the how much to over-sample or under-sample in a class we use the following formula:
where initial
Their proposed model includes balanced augmentation throughout different classes and it outperforms all the baselines.
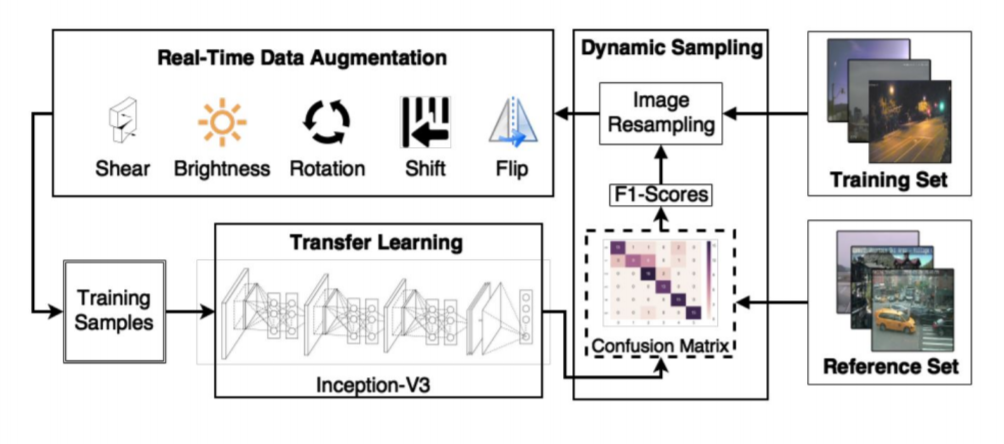
Fig 3. Model proposed by (Pouyanfar et al., 2018) for dynamic sampling
SMOTE-RBM: The SMOTE (Synthetic Minority Over-sampling Technique) method, introduced by Zieba, Tomczak, and Gonczarek (2015), generates artificial samples for minority class data that may not always represent data from the true sample. To solve this limitation, it is combined with RBM (Restricted Boltzmann machine) that applies corrections to the samples generated by SMOTE. An RBM is a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs. The idea of this approach is to construct artificial examples using SMOTE first, and then perform Gibbs sampling with RBM model trained using all minority examples to obtain new sample. In other words, the SMOTE-based sample is a starting point for sampling from RBM model.

Fig 4. Algorithm for creating artificial samples for minority class data with SMOTE together with RBM model.

Fig 5. Examples of different original and artificial images of MNIST data. The first two row are the original examples taken from MNIST data used for generating artificial sample with SMOTE shown in the third row. We can observe that just using SMOTE generates synthetic samples that may not represent samples from the true distribution. Finally, the fourth row has images that is generated with SMOTE and transformed using RBM model.
Algorithm Level Method
Unlike data-level methods, algorithm level methods do not change the distribution of training data. However, they modify the algorithms to account for class penalty or shift the decision threshold to reduce majority class bias. To understand this, we talk about a method called CoSen CNN proposed by (Khan et al., 2015). CoSen CNN refers to a cost-sensitive Convolutional neural network that can automatically learn class-dependent costs and network parameters, and iteratively optimize class-dependent costs and network parameters. This approach is computationally less expensive as compared to the data-level methods and is applicable to both binary and multi-class problems without modification. K. It can be understood as a perturbation method, which forces the training algorithm to learn more discriminative features. By training the network in such a way that different classes are given different priorities, this approach handles the class imbalance problem without changing the data input to the network.
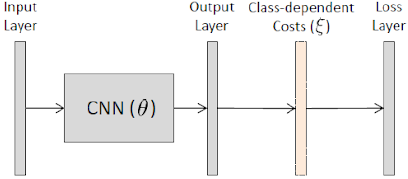
Fig 6. The CNN parameters and class-dependent cost used during the training process.
Hence to summarize CoSen CNN, first we initialize CNN parameters and cost matrix . After that we update by and learning rate . Then update by CNN gradients and learning rate . Finally, we keep alternating between both the updates of and until convergence. As a result, Cosen CNN outperformed basic CNN on different datasets.
Hybrid Method
The hybrid method combines the idea of both data level and algorithm level method. Huang, Li et al. proposed a method called Large Margin Local Embedding that uses a Convolutional neural network to learn an embedding from input data into a feature space such that the embedded features are discriminative without local class imbalance. The motivation of this method is that the minority classes often contain very few instances with high degree of visual variability.
For the experiment, first we create clusters for each classes in the training sets. Now for every query , we find its kNN cluster centroids from all classes learned in the training stage. If all the cluster neighbors belong to the same class, is labelled by that class and exit. Else, we would label as based on the following formula
This is an introduction on how class imbalance in machine learning has been handled throughout the years. We have only covered the main idea for dealing with class imbalance. For more detailed explanation, it is advised to look into the papers in Reference Section.
References
- Problems with imbalanced data
- Anand R, Mehrotra KG, Mohan CK, Ranka S. An improved algorithm for neural network classifcation of imbalanced training sets. IEEE Trans Neural Netw. 1993;4(6):962–9
- Data level methods
- Hensman P, Masko D. The impact of imbalanced training data for convolutional neural networks. 2015.
- Lee H, Park M, Kim J. Plankton classifcation on imbalanced large scale database via convolutional neural networks with transfer learning. In: 2016 IEEE international conference on image processing (ICIP). 2016. p. 3713–7.
- Pouyanfar S, Tao Y, Mohan A, Tian H, Kaseb AS, Gauen K, Dailey R, Aghajanzadeh S, Lu Y, Chen S, Shyu M. Dynamic sampling in convolutional neural networks for imbalanced data classifcation. In: 2018 IEEE conference on multimedia information processing and retrieval (MIPR). 2018. p. 112–7.
- Buda M, Maki A, Mazurowski MA. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018;106:249–59.
- Zieba, Maciej et al. “RBM-SMOTE: Restricted Boltzmann Machines for Synthetic Minority Oversampling Technique.” ACIIDS (2015).
- Algorithm level methods
- Wang S, Liu W, Wu J, Cao L, Meng Q, Kennedy PJ. Training deep neural networks on imbalanced data sets. In: 2016 international joint conference on neural networks (IJCNN). 2016. p. 4368–741
- Lin T-Y, Goyal P, Girshick RB, He K, Doll ́ar P. Focal loss for dense object detection. In: IEEE international conference on computer vision (ICCV). vol. 2017. 2017. p. 2999–3007.
- Wang H, Cui Z, Chen Y, Avidan M, Abdallah AB, Kronzer A. Predicting hospital readmission via cost-sensitive deep learning. IEEE/ACM transactions on computational biology and bioinformatics.
- Zhang C, Tan KC, Ren R. Training cost-sensitive deep belief networks on imbalance data problems. In: 2016 international joint conference on neural networks (IJCNN). 2016. p. 4362–4367.
- Hybrid methods
- Huang C, Li Y, Loy CC, Tang X. Learning deep representation for imbalanced classifcation. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR). 2016. p. 5375–84.
- Ando S, Huang CY. Deep over-sampling framework for classifying imbalanced data. In: Ceci M, Hollm ́en J, Todorovski L, Vens C, Dˇzeroski S, editors. Machine learning and knowledge discovery in databases. Cham: Springer; 2017. p. 770–85.
- Dong Q, Gong S, Zhu X. Imbalanced deep learning by minority class incremental rectifcation. In: IEEE transactions on pattern analysis and machine intelligence. 2018. p. 1–1