Natural Language Processing
Interpreting the State-of-the-art Natural Language Processing Models
Posted by Zhengyang Fan, Zhenlong Jiang and Di Zhang. Presented by Rahul Pandey, Angeela Acharya, Junxiang (Will) Wang and Jomana Bashatah
What is Natural Language Processing
Natural Language Process (NLP) is a computerized approach to analyze and represent naturally occurring texts for the purpose of achieving human-like language processing. In the era of big data, Natural Language Processing has witnessed a variety of applications that include but not limited to
- Machine Translation
- Interactive Voice Response
- Grammar Checking
- Sentiment Analysis
In the blog, we provide a simple introduction to Natural Language Processing that covers common techniques of processing text data and modern applications of deep learning models in NLP.
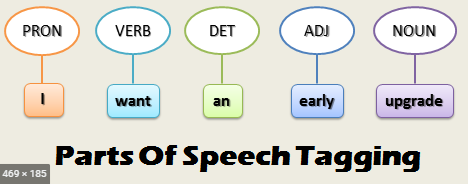
In the sentence “I want an early upgrade” we tag each word as pronoun, verb, noun and so on. One reason of doing Parts-of-speech tagging is that knowing the syntactic role of a word helps with identifying the neighboring words. For example, a noun is normally preceded by determiners and adjectives.
Chunking
In stead of tagging each token or word in a sentence, Chunking combines words into a phrase and assignments a Chunk tag to the entire phrase. For example, South Africa is considered as a single word in Chunking as compared to South and Africa as two separate words in Parts-of-speech tagging. Example of Chunk tags are Noun Phrase, Verb Phrase, etc.
Named Entity Recognition
According to Wikipedia, Named Entity Recognition (NER) is a subtask of information extraction that seeks to locate and classify named entity mentions in unstructured text into pre-defined categories such as the person names, organization, locations, medical codes, time expressions, quantities, monetary values, percentages, etc. Compared to POS-tagging and Chunking, NER provides more semantic information about the content which helps with understanding the major subjects of the text.
Below is an example of Named Entity Recognition. The NER process identifies a person’s name, an organization and a location from the given text.

Semantic Role Labeling
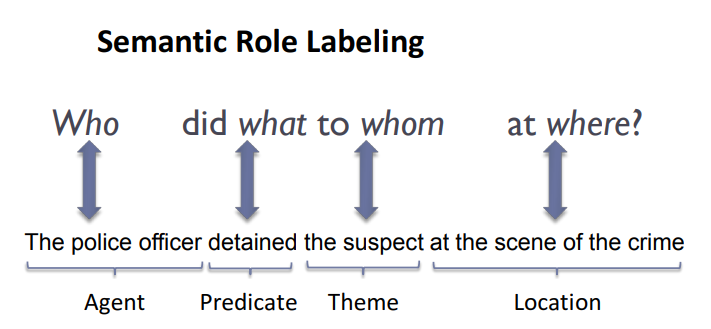
Similar to Named Entity Recognition, Semantic Role Labeling aims to label words or phrase in a sentence based on the structure Who did what to whom at where?. In specific, the Who" part corresponds to agent, the did what part corresponds to predicate, the to whom part corresponds to theme and the at where part corresponds to location. As the name suggested, semantic role labeling extracts major contextual information of a given text by identifying thematic roles of each part of the text. Below is an example of semantic role labeling
Word to Vectors
Besides labeling/tagging words or phases, another way of processing text data is transforming each word into a vector of numbers and this process is formally referred to as Word to Vectors (Word2Vec). One major motivation behind Word2Vec is to account for correlation between words. When words are represented in vector form, the cosin distance between the vector representations of two words gives the degree of similarity between the words.
A common way of constructing vector representation of words is called Skip-gram. In the Skip-gram model, any single word in the source text is treated as an input. The corresponding outputs of an input word is a collection of some adjacent words. Below we show an example of building input-output pairs from a source text using Skip-grams
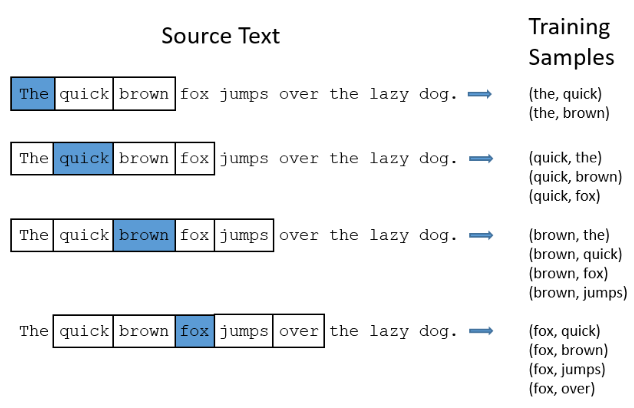
The collection of all input-output pairs are further used as training samples of a two-layer feed-forward neural network. Once the network is trained, the hidden layer for each input (word) is the vector representation of the word.
GloVe
In addition to Word2Vec, GloVe is another well-known technique of constructing vector representations of words. Instead of a neural network, GloVe replies on matrix factorization. It first builds a large matrix of co-occurrence matrix where each word represents a row and the columns denote how frequently the word occurs in each documents belong to a large corpus. Next we factorize the co-occurrence matrix which yields a lower dimensional matrix where each row is the vector representation of the corresponding word.
Hierarchical Attention Network
In this rest of this blog, we will introduce some classical deep learning models in Natural Language Processing. The first one we will discuss is the Hierarchical Attention Network which is widely used for text classification. In the hierarchical attention network, each document has a hierarchical structure where words consist of the bottom of the hierarchy, followed by sentences and then document. To make sure the network captures the essence of the text, an attention scheme is introduced at both word and sentence level where an attention weights is assigned to each word and sentence. A larger attention weight will lead to a heavier impact when making classifications. The figure below shows the structure of a Hierarchical Attention Network.
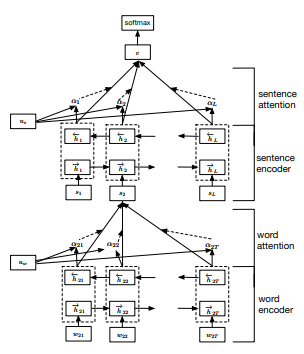
The Hierarchical Attention Network consists of four phases. Given words from a source text, the network starts with a word encoder phase that converts each word to a vector embedding. The vector embedding is further used as inputs of a bi-directional GRU which returns a latent representation of the word. In the second phase, namely the work-level attention phase, the latent representations of words are used as inputs of a multi-layer Perceptron to construct attention weights for each words. Next, a sentence is represented in the network as a weighted average of the latent representations of words belong to the sentence where the weights are simply the attention weights associated with each word. The third and last phase of the network is the same as the first and second phase except that the inputs are sentences instead of words. Finally, a document is represented as a linear combination of latent representations of sentences weighted by the attention weights of each sentence.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Many natural language processing tasks can be improved by language model pre-training. There are 3 different level tasks: sentence-level tasks, paraphrasing and token-level tasks.
There are two existing methods for applying pre-trained language representations to downstream tasks, feature-based and fine-tuning. The same objective function are shared during pre-training. Inaddition, these mothods apply unidirectional language models to learn general language representations.
Unidirectional is the major limitation for current methods of standard language models which have negative effect on the the choice of architectures durning pre-training. In the presentation, the NLP team propose a different directional method, BERT. The new method can use a “masked language model” (MLM) pre-training objective to alleviates the previously mentioned unidirectionality constraint.
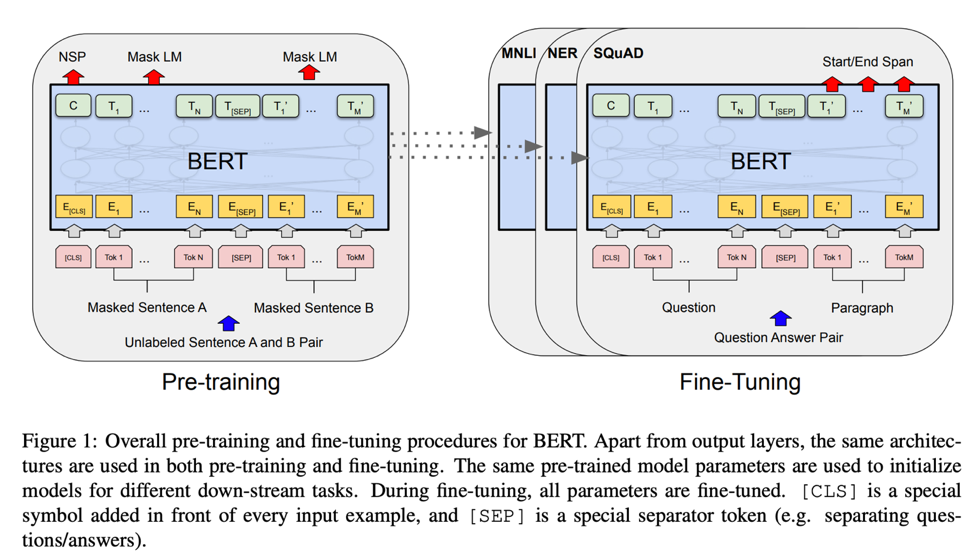
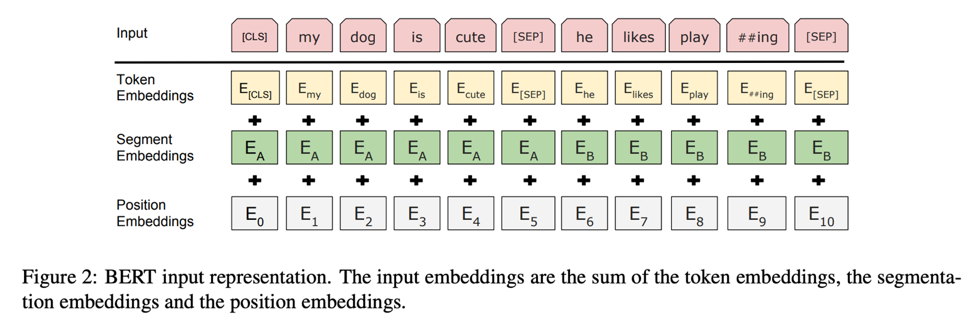
Transformer Architecture
The dominant sequence transduction models are made by complex recurrent or convolutional neural networks including an encoder and a decoder.
The NLP team presented a new simple network architecture which is the Transformer. The transformer are based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. The Transformer follows the following architecture which can use stacked self-attention and point-wise, fully connected layers during the encoder and decoder. The following Figure shows the architecture.
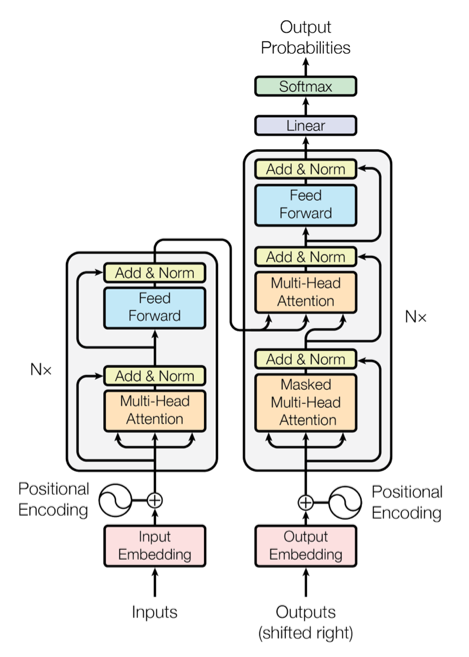
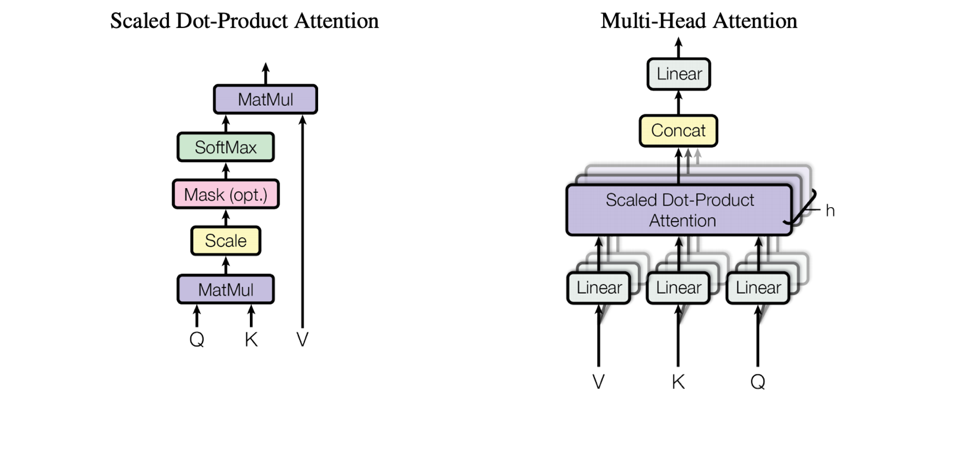
The key points of the attention function are mapping a query and a set of key-value pairs to an output. All the query, keys, values, and output are vector based. The output can be calculated as weighted sum of the values which the weights can be generated by the compatibility function of the query with the corresponding key.
The following figure shows two different attention: